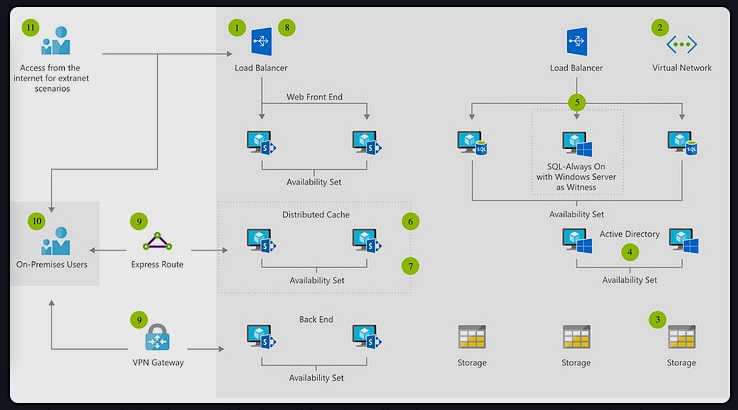
Autoren: Marius Hug, Matthias Boenig, Yannic Bracke, Frank Fischer, Susanne Haaf, Christian Thomas
Intro
Im folgenden Beitrag soll gezeigt werden, wie deutschsprachige Dramen aus den zwei Textsammlungen TextGrid Repository (TGRep) und German Drama Corpus (GerDraCor) unter Einbeziehung von Metadaten aus einer externen Katalogdatei in das Basisformat des Deutschen Textarchivs (DTABf) transformiert werden. Die Dramen stellen im TGR ein Subkorpus der „Digitalen Bibliothek“ dar und wurden, wie auch der Metadatenkatalog, ursprünglich von zeno.org publiziert. Dieser UseCase mit dem Ziel der gegenseitigen Bereicherung wurde im Rahmen des CLARIAH-DE-Projektes realisiert.
Das zeno.org-Drama im TextGrid Repository
Das TextGrid Repository ist ein Langzeitarchiv für geisteswissenschaftliche Forschungsdaten. Es liefert einen umfangreichen, durchsuch- und nachnutzbaren Bestand an Texten und Bildern. Grundstock des Archivs ist die bereits in den 1990er Jahren vom Verlag Directmedia Publishing herausgegebene „Digitale Bibliothek“. Das TextGrid Repository stellt diese nach den Richtlinien der Text Encoding Initiative (TEI) konvertierte Textsammlung – genauer: den Ordner „Literatur“ – ohne Werbung unter einer Creative-Commons-Lizenz zur Verfügung, bietet eine nachhaltige Speicherung sowie Zitierfähigkeit. Die Texte können zu eigenen Sammlungen zusammengestellt und heruntergeladen werden, zudem können neue Möglichkeiten der Analyse von Texte – bspw. durch die Anbindung an den Service Digivoy – genutzt werden.
Die Inhalte des TGRep sind explorativ durch Filter nach Genre – außerdem nach Autor, Dateityp und Projekt – erkundbar. Der Genre-Filter erlaubt (Stand 2020-05) Zugriff auf:
- verse (118083 items)
- other (58833 items)
- prose (6663 items)
- drama (1462 items)
- non-fiction (2 items)
Dabei ist die Zählung der items projektspezifischen Entscheidungen über die Speicherung der Metadaten geschuldet. Anstatt dies an dieser Stelle weiter auszuführen, sei auf den ausführlichen BlogPost von Frank Fischer und Mathias Göbel zu diesem Thema1 verwiesen werden, in welchem die Auswirkungen dieser Praxis äußerst detailliert nachvollzogen werden kann. Nur soviel: Es gibt im TGRep keine 1462 Dramen, sondern ‚nur‘ 666.
Mit dem in einer Pressemitteilung der Georg-August-Universität Göttingen am 2. Dezember 2009 gemeldeten Erwerb der „Digitalen Bibliothek“, kam der Forschungsverbund TextGrid neben der umfangreichen Textsammlung auch in den Besitz einer Katalogdatei. Dieser Katalog enthält die kompletten Metadaten der Quellen, aus denen die einzelnen Texte stammen und wird für die Erschließung der „Digitalen Bibliothek“ genutzt.
Beispielsweise ist das Drama „Die deutschen Kleinstädter“ von August von Kotzebue darin folgendermaßen vermerkt (siehe Abb. 1): Die drei zentralen Elemente der Beschreibung sind <BOOKNAME>, <BOOKDESCR> und <BOOKCITE>.2 Sowohl <BOOKDESCR> wie auch <BOOKCITE> enthalten jeweils bibliographische Angaben zum in Frage stehenden Werk, jedoch von unterschiedlichem Detailgrad. Gemein ist beiden, dass die darin enthaltenen Informationen nicht mit einem Markup strukturiert vorliegen. Nur mit Hilfe von Heuristiken können die Informationen wie Personenname, Titel, Erscheinungsort oder Erscheinungsjahr extrahiert werden.

Abb. 1: Bibliographischer Eintrag im zeno.org-Katalog.
Für die Online-Version des TGRep wurde auf das <BOOKDESCR>-Element zurückgegriffen. Diese Entscheidung ist in diesem Falle verständlich, würden doch ansonsten Informationen (Hrsg., Verlag etc.) verloren gehen. Zudem wurde der Autor als solcher (<author>) annotiert und mit einer Identifikationsnummer (ID) aus der Gemeinsamen Normdatei (GND) versehen, der Erscheinungsort sowie das Erscheinungsdatum wurden getaggt.3
Was im Screenshot (siehe Abb. 2) nach einer echten Aufwertung der Metadaten aussieht, hat aber bei der Übernahme der Daten von zeno.org nach TextGrid nicht in allen Fällen reibungslos funktioniert, d.h. in einigen Fällen fehlt das Datum, in anderen sogar die komplette hier als <title> annotierte bibliographische Angabe. Zudem wird die Entscheidung, ausschließlich den Inhalt von <BOOKDESCR> als <title> in die <sourceDesc> zu übernehmen, immer dann problematisch, wenn es sich um mehrbändige Werke handelt. Die Information, um welches Werk genau es sich handelt, geht dann zugunsten einer allgemeinen Information über die Gesamtzahl der Bände verloren.

Abb. 2: Kotzebue: Die deutschen Kleinstädter, TGRep-Version der <sourceDesc>.
German Drama Corpus (GerDraCor)
Als Subkorpus der DraCor-Plattform enthält das German Drama Corpus (GerDraCor)4 zurzeit insgesamt 496 Dramen, von denen 469 der ursprünglich von zeno.org erstellten und zwischenzeitlich in das TGRep integrierten „Digitalen Bibliothek” entstammen. Mit den unter einer CC-Lizenz zur Verfügung gestellten Dramen im TEI P5-Format stellt GerDraCor das Referenzkorpus im Kontext (deutschsprachiger) Dramenanalyse dar.
Über eine Schnittstelle (API) erleichtert die DraCor-Plattform die Recherche über die verschiedenen Teilkorpora, wobei die Modularität der Plattform die Trennung von Korpuspflege und forschungsgetriebenem technology stack ermöglicht. So liefert die API auf der Grundlage des gemeinsamen Auftretens von Charakteren (sprechenden Entitäten) in verschiedenen Szenen beispielsweise Daten für jedes Theaterstück. Diese werden zur Laufzeit aus der zugrundeliegenden TEI-Datei extrahiert und können für moderne Netzwerk-Visualisierungen (mit Gephi, Cytoscape oder ähnlichen Programmen) verwendet werden.

Abb. 3: Screenshot des GerDraCor-GitHub-Repository.
Die 469 TGRep-Dramen von GerDraCor stammen aus insgesamt nur 233 Quellen, die ursprünglich als implizites Subkorpus der „Digitalen Bibliothek“ von zeno.org zur Verfügung gestellt wurden. Aufgrund des klar abgesteckten Korpusumfangs konnten dabei einige Korrekturen und Verbesserungen an den Daten vorgenommen werden. So wurden beispielsweise bestimmte Textstellen händisch eingefügt, die bei der Konvertierung der Dramen aus dem zeno.org-XML in das TextGrid Baseline Encoding (d.i. der im TGRep verwendete TEI-Dialekt) verloren gegangenen waren. Darüber hinaus gab es einige Verbesserungen im Bereich der Metadaten.
GerDraCor hat die Quellenangaben für die sogenannte <sourceDesc> im TEIHeader größtenteils aus den TGRep-Daten übernommen. Während im TGRep die gesamte bibliographische Angabe als <title> innerhalb von <biblFull> annotiert wurde – was nicht den TEI-Richtlinien entspricht, allerdings aufgrund der Korpusgröße und den unzureichenden Annotationen der vorliegenden Originaldaten von zeno.org erklärt werden kann –, spezifiziert GerDraCor diese innerhalb der <sourceDesc> als <title> in einem <bibl> mit dem Attribut „originalSource“ (siehe Abb. 4). Ein echter Mehrwert ist die händische Anreicherung der Datumsangaben sowie der Sprecher5 und der IDs, welche im Rahmen der hier beschriebenen wechselseitigen Bereicherung verschiedener Textsammlungen aus den GerDraCor-Daten in das DTA-Subkorpus integriert werden können. Der eindeutige Identifier (ID) zur TGRep-Ressource ist ebenso Teil der <sourceDesc> wie auch ein Hinweis auf die Lizenz.
Die für die Forschung wichtigen Datumsangaben (<dates>) wurden überprüft und korrigiert. Da die von zeno.org verwendeten Ausgaben oftmals keine Rückschlüsse auf das Entstehungsdatum, das Datum der ersten Vorführung des Schauspiels etc. zulassen, wurden diese Informationen von GerDraCor nachrecherchiert. Die <date>-Elemente wurden über das Attribut @type (mit den Werten „print“, „premiere“ und „written“) differenziert. Diese Anreicherung der <sourceDesc> war auch deswegen wichtig, da in der TGRep-Version mehr als 10% der in Frage stehenden Dramen gar kein Erscheinungsjahr enthielten.

Abb. 4: Kotzebue: Die deutschen Kleinstädter, GerDraCor-Version der <sourceDesc>.
Auch in der GerDraCor-Version fehlt leider die Möglichkeit, auf die einzelnen bibliographischen Informationen (Autor, Titel, Verlag etc.) zuzugreifen.
Dramen im Deutschen Textarchiv
Das Deutsche Textarchiv (DTA) an der Berlin-Brandenburgischen Akademie der Wissenschaften stellt einen disziplinen- und gattungsübergreifenden Grundbestand von deutschsprachigen Texten ab dem frühen 16. bis zum frühen 20. Jahrhundert bereit. Hauptziel des Projekts war die Erstellung des sogenannten DTA-Kernkorpus. Dieses enthält insgesamt 1468 Werke (Stand 2020-03) aus dem Zeitraum von ca. 1600 bis 1900, die aufgrund ihrer herausragenden Bedeutung für die Entwicklung der deutschen Sprache bzw. der jeweiligen Genres und wissenschaftlichen Disziplinen ausgewählt wurden. Das Standardverfahren der Texterfassung war das sogenannte Double-Keying.

Abb. 5: Webpräsenz des Deutschen Textarchivs (DTA).
Über das DTA-Kernkorpus hinaus integriert das DTA eine Vielzahl weiterer Texte aus dem Zeitraum etwa von der Mitte des 15. bis zur Mitte des 20. Jahrhunderts als DTA-Erweiterungen (DTAE). Diese stammen aus kooperierenden Projekten und weiteren externen Quellen (siehe Abb. 6). Grundsätzlich haben alle Wissenschaftler*innen, die im Rahmen ihrer Arbeiten, ihrer Projekte oder ihrer Editionen Texte des späten 16. bis frühen 20. Jahrhunderts digitalisieren und bearbeiten, die Möglichkeit, diese Texte im Modul DTAE zu veröffentlichen. Während das DTA so durch Primärtexte aus anderen Projektkontexten fortlaufend ergänzt wird, können diese angelagerten Texte als Spezialkorpora zudem mit dem DTA-Kernkorpus auf ihre sprachlichen Spezifika hin verglichen werden.

Abb. 6: Visualisierung ausgewählte Teilprojekte innerhalb von DTAE, mit Angabe der in das DTA übernommen Seiten aus den jeweiligen Quellen.
Das DTAE (5014 Werke, Stand 2020-03) enthält somit verschiedene (explizite) Subkorpora, wie bspw. die in den Projekten Alexander von Humboldts Kosmos-Vorträge, dem Briefwechsel Daniel Sanders, DSDK u.v.a. erstellten und in die CLARIN-D-Infrastruktur der BBAW integrierten Textressourcen. Gleichzeitig besteht aufgrund entsprechender Zuordnung in den Metadaten der Texte die Möglichkeit, über geeignete Filter bzw. Sucheinschränkungen, eigene Subkorpora zu generieren. Hier erweist sich die im DTA implementierte DDC-Suche als mächtiges Tool. So kann über das sogenannte „flags“ direkt auf Subkorpora zugegriffen werden. Aber auch ein Zugriff auf die Metadaten, die im TEIHeader gespeichert sind, ist möglich, z.B.:
| #has[flags,/\bwikisource\b/] | schränkt die Suche auf das Wikisource-Korpus ein |
| #has[textClassDTA,’Belletristik::Drama‘] | Sucheinschränkung auf Dramen innerhalb der Metadaten |
Bereicherung über das CLARIAH-DE-Pivotformat DTABf
Das DTA hat mit dem sogenannten Basisformat (DTABf) einen mittlerweile etablierten Standard im Bereich TEI-Annotation historischer Texte geschaffen. Im DTABf wird für den Quellennachweis innerhalb des TEIHeaders (<sourceDesc>) sowohl <biblFull> als auch <bibl> verwendet. In der Konvertierung der Dramen aus dem TGRep in das DTABf werden die bibliographischen Angaben des Originals – so wie sie vorliegen – im Element <bibl> gespeichert. Die DTABf-konforme Angabe eines <title> innerhalb eines <biblFull> ist auf diesem Weg aber ebenso wenig möglich wie bei den oben beschriebenen Plattformen. Der Grund liegt schlicht darin, dass der Titel der Quelle sowie weitere bibliographische Angaben bislang nicht isoliert (annotiert) vorliegen.
Erst der Abgleich mit einem im Projekt CLARIAH-DE händisch annotierten Quellenverzeichnis (siehe Abb. 7) macht es endlich möglich, ein vollständiges <sourceDesc> gemäß TEI zu generieren. Und diese <sourceDesc> wird neben der über Attribute (@type und @level) weiter spezifizierten Titelangabe (<title>) und den beteiligten Akteuren (<persName> als Autor oder Editor inkl. einer eindeutigen ID per GND) auch einen Verlag (<publisher>), einen Erscheinungsort (<pubPlace>), eine Datumsangabe (<date>) und gegebenenfalls weitere Angaben bspw. per <biblScope> enthalten.

Abb. 7: Ausschnitt aus der im Projekt CLARIAH-DE angereicherten Bibliographie der Digitalen Bibliothek.
Für das tief strukturierte Quellenverzeichnis wurde auf die Katalogdatei von zeno.org zurückgegriffen. Die GND-IDs wurden größtenteils aus den TGRep-Daten extrahiert. Diese aufwendige Anreicherung der bibliographischen Angaben der von zeno.org bereitgestellten Katalogdatei bildet die Voraussetzung für die geplante Konvertierung der „Digitalen Bibliothek“ in das Basisformat des Deutschen Textarchivs (DTABf).
Für die Erstellung des TEIHeaders wird zunächst über ein Mapping auf Basis des zeno.org-Identifiers <BOOKNAME> diejenige Quelle ermittelt, aus welcher das Werk stammt.6 Es folgt ein Zugriff auf den im Projekt erstellten und angereicherten Katalogdatensatz. Um die Verlinkung mit dem ursprünglichen Datensatz zu gewährleisten, wird aus den TGRep-Daten der TextGrid-URI (d.h. Uniform Resource Identifier) übernommen.7 Da es sich in den allermeisten Fällen bei den zeno.org-Ausgaben nicht um die Erstausgabe handelt, muss schließlich der Titel des Werks aus einem <titleStmt> in der <fileDesc> im TGRep-Header übernommen werden. Für einen entsprechenden Ausschnitt aus dem so generierten TEI-Header siehe Abb. 8:

Abb. 8: Kotzebue: Die deutschen Kleinstädter, DTABf-Version der <sourceDesc>, die im Projekt CLARIAH-DE erstellt wird.
Daran anschließend können die so aufgewerteten TEIHeader der Dramen per script vollautomatisch in die entsprechenden GerDraCor-Dateien zurückgespielt werden. Schließlich können die so angereicherten TGRep-Textderivate auch über einen URI in den Metadaten der jeweiligen Ressourcen Teil der TGRep-Datensätze werden.
Neben diesen offensichtlichen Synergieeffekten, von denen alle drei Textsammlungen – das TextGrid Repository, die GerDraCor-Plattform sowie das Deutsche Textarchiv – profitieren, wird die Kuration der TGrep-TEI-Version der von zeno.org erstellten digitalen Texte sowie die Konvertierung in das DTABf weitere Vorteile bringen:
- Zukünftig wird die Beforschung der „Digitalen Bibliothek“ im Kontext anderer Textsammlungen (wie dem Deutschen Textarchiv (DTA)) möglich sein.
- Es werden weitere etablierte Tools im Bereich der Sprachforschung zur Verfügung stehen, um die Textsammlung zu analysieren.
- Die Bereinigung und Anreicherung der Metadaten wird es möglich machen, aus dem Bestand die verschiedenen Ausgaben der Texte zu identifizieren und zu kollationieren.
- Nicht zuletzt können durch die Integration der Textsammlung in die CLARIN-D-Infrastruktur der BBAW einige sehr avancierte Suchfunktionen und Analysewerkzeuge genutzt werden.
Referenzen
Frank Fischer, Ingo Börner, Mathias Göbel, Angelika Hechtl, Christopher Kittel, Carsten Milling and Peer Trilcke (2019): „Programmable Corpora. Die digitale Literaturwissenschaft zwischen Forschung und Infrastruktur am Beispiel von DraCor.“ In: DHd 2019. Digital Humanities: multimedial & multimodal. Konferenzabstracts, pp. 194–197. DOI: 10.5281/zenodo.2596094.
Frank Fischer, Susanne Haaf, und Marius Hug. „The Best of Three Worlds: Mutual Enhancement of Corpora of Dramatic Texts (GerDraCor, German Text Archive, TextGrid Repository)“. In Proceedings of CLARIN Annual Conference 2019, herausgegeben von K. Simov und M. Eskevich, 97–103. Leipzig, 2019. URL: https://office.clarin.eu/v/CE-2019-1512_CLARIN2019_ConferenceProceedings.pdf#page=104.
Frank Fischer, Mathias Göbel: „A (Not So) Simple Question and a Somewhat Diabolic Answer“, June 18, 2015. URL: https://dlina.github.io/A-Not-So-Simple-Question/.
Alexander Geyken, Matthias Boenig, Susanne Haaf, Bryan Jurish, Christian Thomas, Frank Wiegand: „Das Deutsche Textarchiv als Forschungsplattform für historische Daten in CLARIN.“ In: Henning Lobin, Roman Schneider, Andreas Witt (Hgg.): Digitale Infrastrukturen für die germanistische Forschung (= Germanistische Sprachwissenschaft um 2020, Bd. 6). Berlin/Boston, 2018, S. 219–248. Online-Version, DOI: 10.1515/9783110538663-011.
Alexander Geyken, Thomas Gloning: „A living text archive of 15th-19th-century German. Corpus strategies, technology, organization.“ In: Jost Gippert, Ralf Gehrke (Hrsg.): Historical Corpora. Challenges and Perspectives. Tübingen 2015, S. 165–180.
- Digital Literary Network Analysis (dlina): „A (Not So) Simple Question and a Somewhat Diabolic Answer“, June 18, 2015, https://dlina.github.io/A-Not-So-Simple-Question/ [Diese und alle URLs in diesem Beitrag zuletzt abgerufen 2020-06-19].
- Zwar ist <BOOKNAME> ein wichtiger und eindeutiger Identifier innerhalb von Zeno.org, da dieser im TGRep aber keine Rolle spielt, wird auch hier nicht näher auf ihn eingegangen.
- Neben der Online-Version im TextGrid Repository stehen auch zwei Versionen zum Download zur Verfügung. Beide Versionen machen von <BOOKDESCR> Gebrauch und verlieren dabei, s.o., die Zuordnung bei mehrbändigen Werken. Zusätzlich gibt es einen momentan nicht öffentlich zugänglichen Arbeitsstand mit einigen Korrekturen von 2017. In diesem werden als Quellennachweis zwei <title> angegeben, wobei es sich um 1:1-Übernahmen von <BOOKDESCR> und <BOOKCITE> handelt.
- Siehe zu GerDraCor: https://dracor.org/ger, https://github.com/dracor-org/gerdracor, https://github.com/dracor-org/gerdracor/wiki/Documentation-for-Correcting-Plays-from-TextGrid-Repository.
- Im Rahmen der hier beschriebenen wechselseitigen Bereicherung verschiedener Textsammlungen können diese <speaker> aus den GerDraCor-Daten in das DTA-Subkorpus integriert werden. Da diese jedoch nicht Teil der <sourceDesc> sind, kann man sie auf dem Screenshot nicht sehen.
- Was dabei auf der Buchebene oftmals noch relativ trivial erscheint, wird schnell komplex, wenn es sich bei dem bearbeiteten Titel nur um einen Teil eines Werks handelt. Nötig ist der Rückgriff auf die zeno.org-Information, da in einem nicht zu vernachlässigenden Teil der TGRep-Daten überhaupt keine <title>-Daten übernommen wurden.
- Dies klingt in der Tat einfacher, als es sich darstellt, denn in der ansonsten zu bevorzugenden 2017er-Version der TGRep-Daten fehlen just diese IDs.